Popular Entries all / by tag / by year / popular
Redis and the Cost of Ambition

And they said, Go to, let us build us a city and a tower, whose top may reach unto heaven; and let us make us a name, lest we be scattered abroad upon the face of the whole earth.
What happened to dear old Redis, I wondered. And the more I thought about it, a satisfying explanation started to coalesce which explains all the above phenomena. To me, the picture that emerges is that of a solution that lost its identity through ambition.
Tokens and Dreams
The one great principle of the English law is, to make business for itself.

The map is not the territory.
This is why I'm stuck. I'm stuck between competing narratives, each of which is exerting real business pressure. To push-back when people's daily experience of AI is of the magical variety is seen as almost perverse. I find myself constantly wanting to say "No! I embrace these tools! This is not thinly-veiled self-preservation! Just hear me out..."
Slopification and Its Discontents

O sovran, virtuous, precious of all trees
In Paradise! of operation blest
To sapience, hitherto obscured, infamed.
A couple weeks back Anthropic announced a promotion offering six free months of their maximum Claude plan to open-source developers. I submitted an application, and a few days later an invitation arrived in my inbox and I was up-and-running on the latest Opus 4.6 model.
The fruit was plucked and in my hand.
Ghost in the Shell: my AI Experiment
A man's at odds to know his mind cause his mind is aught he has to know it with. He can know his heart, but he dont want to. Rightly so. Best not to look in there. It aint the heart of a creature that is bound in the way that God has set for it. You can find meanness in the least of creatures, but when God made man the devil was at his elbow. A creature that can do anything. Make a machine. And a machine to make the machine. An evil that can run itself a thousand years, no need to tend it.
This isn't a post about the machines, though. It is always the human builder that comes first and last.
AsyncIO

I'd like to put forth my current thinking about asyncio. I hope this will answer some of the questions I've received as to whether Peewee will one day support asyncio, but moreso I hope it will encourage some readers (especially in the web development crowd) to question whether asyncio is appropriate for their project, and if so, look into alternatives like gevent.
New features planned for Python 4.0
With the release of Python 3.8 coming soon, the core development team has asked me to summarize our latest discussions on the new features planned for Python 4.0, codename "ouroboros: the snake will eat itself". This will be an exciting release and a significant milestone, many thanks to the hard work of over 100 contributors.
Kyoto Tycoon in 2019
![]()
I've been interested in using Kyoto Tycoon for some time. Kyoto Tycoon, successor to Tokyo Tyrant, is a key/value database with a number of desirable features:
- On-disk hash table for fast random access
- On-disk b-tree for ordered collections
- Server supports thousands of concurrent connections
- Embedded lua scripting
- Asynchronous replication, hot backups, update logging
- Exceptional performance
Write your own miniature Redis with Python
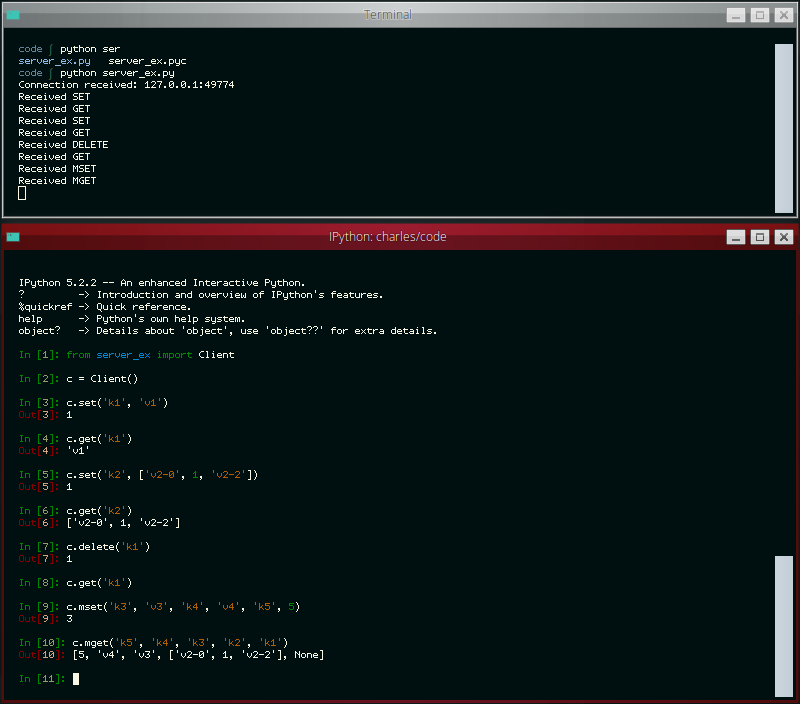
The other day the idea occurred to me that it would be neat to write a simple Redis-like database server. While I've had plenty of experience with WSGI applications, a database server presented a novel challenge and proved to be a nice practical way of learning how to work with sockets in Python. In this post I'll share what I learned along the way.
The goal of my project was to write a simple server that I could use with a task queue project of mine called huey. Huey uses Redis as the default storage engine for tracking enqueued jobs, results of finished jobs, and other things. For the purposes of this post, I've reduced the scope of the original project even further so as not to muddy the waters with code you could very easily write yourself, but if you're curious, you can check out the end result here (documentation).
The server we'll be building will be able to respond to the following commands:
- GET
<key> - SET
<key><value> - DELETE
<key> - FLUSH
- MGET
<key1>...<keyn> - MSET
<key1><value1>...<keyn><valuen>
We'll support the following data-types as well:
- Strings and Binary Data
- Numbers
- NULL
- Arrays (which may be nested)
- Dictionaries (which may be nested)
- Error messages
Going Fast with SQLite and Python
![]()
In this post I'd like to share with you some techniques for effectively working with SQLite using Python. SQLite is a capable library, providing an in-process relational database for efficient storage of small-to-medium-sized data sets. It supports most of the common features of SQL with few exceptions. Best of all, most Python users do not need to install anything to get started working with SQLite, as the standard library in most distributions ships with the sqlite3 module.
Nginx: a caching, thumbnailing, reverse proxying image server?
![]()
A month or two ago, I decided to remove Varnish from my site and replace it with Nginx's built-in caching system. I was already using Nginx to proxy to my Python sites, so getting rid of Varnish meant one less thing to fiddle with. I spent a few days reading up on how to configure Nginx's cache and overhauling the various config files for my Python sites (so much for saving time). In the course of my reading I bookmarked a number of interesting Nginx modules to return to, among them the Image Filter module.
Five reasons you should use SQLite in 2016
![]()
If you haven't heard, SQLite is an amazing database capable of doing real work in real production environments. In this post, I'll outline 5 reasons why I think you should use SQLite in 2016.
Announcing sophy: fast Python bindings for Sophia Database
![]()
Sophia is a powerful key/value database with loads of features packed into a simple C API. In order to use this database in some upcoming projects I've got planned, I decided to write some Python bindings and the result is sophy. In this post, I'll describe the features of Sophia database, and then show example code using sophy, the Python wrapper.
Here is an overview of the features of the Sophia database:
- Append-only MVCC database
- ACID transactions
- Consistent cursors
- Compression
- Ordered key/value store
- Range searches
- Prefix searches
Using the SQLite JSON1 and FTS5 Extensions with Python
Back in September, word started getting around trendy programming circles about a new file that had appeared in the SQLite fossil repo named json1.c. I originally wrote up a post that contained some gross hacks in order to get pysqlite to compile and work with the new json1 extension. With the release of SQLite 3.9.0, those hacks are no longer necessary.
SQLite 3.9.0 is a fantastic release. In addition to the much anticipated json1 extension, there is a new version of the full-text search extension called fts5. fts5 improves performance of complex search queries and provides an out-of-the-box BM25 ranking implementation. You can also boost the significance of particular fields in the ranking. I suggest you check out the release notes for the full list of enhancements
This post will describe how to compile SQLite with support for json1 and fts5. We'll use the new SQLite library to compile a python driver so we can use the new features from python. Because I really like pysqlite and apsw, I've included instructions for building both of them. Finally, we'll use peewee ORM to run queries using the json1 and fts5 extensions.
Introduction to the fast new UnQLite Python Bindings
![]()
About a year ago, I blogged about some Python bindings I wrote for the embedded NoSQL document store UnQLite. One year later I'm happy to announce that I've rewritten the library using Cython and operations are, in most cases, an order of magnitude faster.
This was my first real attempt at using Cython and the experience was just the right mix of challenging and rewarding. I bought the O'Reilly Cython Book which came in super handy, so if you're interested in getting started with Cython I recommend picking up a copy.
In this post I'll quickly touch on the features of UnQLite, then show you how to use the Python bindings. When you're done reading you should hopefully be ready to use UnQLite in your next Python project.
Meet Scout, a Search Server Powered by SQLite

In my continuing adventures with SQLite, I had the idea of writing a RESTful search server utilizing SQLite's full-text search extension. You might think of it as a poor man's ElasticSearch.
So what is this project? Well, the idea I had was that instead of building out separate search implementations for my various projects, I would build a single lightweight search service I could use everywhere. I really like SQLite (and have previously blogged about using SQLite's full-text search with Python), and the full-text search extension is quite good, so it didn't require much imagination to take the next leap and expose it as a web-service.
Read on for more details.
How to make a Flask blog in one hour or less
For fun, I thought I'd write a post describing how to build a blog using Flask, a Python web-framework. Building a blog seems like, along with writing a Twitter-clone, a quintessential experience when learning a new web framework. I remember when I was attending a five-day Django tutorial presented by Jacob Kaplan-Moss, one of my favorite projects we did was creating a blog. After setting up the core of the site, I spent a ton of time adding features and little tweaks here-and-there. My hope is that this post will give you the tools to build a blog, and that you have fun customizing the site and adding cool new features.
In this post we'll cover the basics to get a functional site, but leave lots of room for personalization and improvements so you can make it your own. The actual Python source code for the blog will be a very manageable 200 lines.
Who is this post for?
This post is intended for beginner to intermediate-level Python developers, or experienced developers looking to learn a bit more about Python and Flask. For the mother of all Flask tutorials, check out Miguel Grinberg's 18 part Flask mega-tutorial.
The spec
Here are the features:
- Entries are formatted using markdown.
- Entries support syntax highlighting, optionally using Github-style triple-backticks.
- Automatic video / rich media embedding using OEmbed.
- Very nice full-text search thanks to SQLite's FTS extension.
- Pagination.
- Draft posts.
Walrus: Lightweight Python utilities for working with Redis
![]()
A couple weekends ago I got it into my head that I would build a thin Python wrapper for working with Redis. Andy McCurdy's redis-py is a fantastic low-level client library with built-in support for connection-pooling and pipelining, but it does little more than provide an interface to Redis' built-in commands (and rightly so). I decided to build a project on top of redis-py that exposed pythonic containers for the Redis data-types. I went on to add a few extras, including a cache and a declarative model layer. The result is walrus.
Querying Tree Structures in SQLite using Python and the Transitive Closure Extension

I recently read a good write-up on tree structures in PostgreSQL. Hierarchical data is notoriously tricky to model in a relational database, and a variety of techniques have grown out of developers' attempts to optimize for certain types of queries.
In his post, Graeme describes several approaches to modeling trees, including:
- Adjancency models, in which each node in the tree contains a foreign key to its parent row.
- Materialized path model, in which each node stores its ancestral path in a denormalized column. Typically the path is stored as a string separated by a delimiter, e.g. "{root id}.{child id}.{grandchild id}".
- Nested sets, in which each node defines an interval that encompasses a range of child nodes.
- PostgreSQL arrays, in which the materialized path is stored in an array, and general inverted indexes are used to efficiently query the path.
In the comments, some users pointed out that the ltree extension could also be used to efficiently store and query materialized paths. LTrees support two powerful query languages (lquery and ltxtquery) for pattern-matching LTree labels and performing full-text searches on labels.
One technique that was not discussed in Graeme's post was the use of closure tables. A closure table is a many-to-many junction table storing all relationships between nodes in a tree. It is related to the adjacency model, in that each database row still stores a reference to its parent row. The closure table gets its name from the additional table, which stores each combination of ancestor/child nodes.
Web-based SQLite Database Browser, powered by Flask and Peewee

For the past week or two I've been spending some of my spare time working on a web-based SQLite database browser. I thought this would be a useful project, because I've switched all my personal projects over to SQLite and foresee using it for pretty much everything. It also dovetailed with some work I'd been doing lately on peewee regarding reflection and code generation. So it seemed like some pretty good bang/buck, especially given my perception that there weren't many SQLite browsers out there (it turns out there are quite a few, however). I'm sharing it in the hopes that other devs (and non-devs?) find it useful.
Saturday morning hacks: Building an Analytics App with Flask

A couple years back I wrote about building an Analytics service with Cassandra. As fun as that project was to build, the reality was that Cassandra was completely unsuitable for my actual needs, so I decided to switch to something simpler. I'm happy to say the replacement app has been running without a hitch for the past 5 months taking up only about 20 MB of RAM! In this post I'll show how to build a lightweight Analytics service using Flask.